


Over the years, Machine Learning has always been useful for solving real-life problems always. But, these days, it is widely used in every sector. The fields includes medical areas, e-commerce businesses, banking & finance, insurance companies, etc. Previously, all these reviewing tasks were manually accomplished by staffs.
However, because of the continuous rise in the processing power of systems as well as advancement in statistical analysis, everyone is accepting Machine Learning in every sector at an increasing rate. For the purpose of this article, we will look at fraud detection algorithms using Machine Learning. See More Updates for Fraud Detection Algorithms Using Machine Learning and AI here.
You can also search for the following for more details;
- Best fraud detection using machine learning python
- Top fraud-detection using machine learning github
- New fraud detection machine learning case study
- Fraud detection using machine learning kaggle
- E-commerce fraud detection machine learning
- Fraud detection in banking using deep reinforcement learning
- Credit-card-fraud-detection using machine learning techniques
- The category of machine learning/ai algorithms used to detect insurance fraud
Overview Intro to Fraud Detection Algorithms in Machine Learning
Over the years, scam/fraud has been a trending issue in different sectors. Basically, banking, medical institutions, insurance organisations, and many others has been affected by this. The question is how? Because of the growing number of online transactions through different payment options, many has been scammed. Payment options such as mobile credit/debit cards, Gpay, Paytm, PhonePe, etc., has made fraudulent activities to increase.
Generally, criminals or online fraudsters are becoming very experienced in finding loop holes so that they can steals from people/organisations. You will agree that no system is 100% perfectly secure. Therefore, there is always a loophole them. This has become a challenging task to make a secure system for authentication and securing real customers from being defrauded. That being said, fraud detection algorithms are very useful tools for preventing frauds.
Continue reading below for Machine Learning guide which can be used for creating a fraud detection algorithm that helps people in solving these real-life problems.
Types of Internet Fraud
- Email Phishing
- Payment Fraud
- ID Document Forgery
- Identity Theft
1. Email Phishing:
In this type of internet fraud, cybercrime attackers send fake sites and messages to users through email. These emails arrive in your inbox just like any other mail. When you see the message, it looks seemingly legit & authentic. Anyone can easily misjudge them and click on them. That puts you at risk because, the links steals vulnerable data from your computer.
How do you prevent email phishing? Practically, the best proven way to prevent email phishing is to completely avoid clicking on unverified/untrustworthy links. Secondly, do not enter important vulnerable data in these emails until you verify the source as well as their credentials. Thirdly, the best way is to ignore these emails or text messages that flash on your screen. Possibly, delete these mails immediately. Fundamentally, the traditional methods for phishing involve the use of filters. These filters are primarily of two types. First, the authentication protection and secondly, the network-level protection. The Authentication protection is through email verification request. Network-level protection is through three filters; whitelist, blacklist, and pattern matching. So, all these methods are automated through classical Machine Learning algorithms. They use them for classification and regression.
2. Payment Fraud:
The payment fraud is very common in today’s card systems for online banking. These fraudsters can trickily steal card details, make counterfeit cards (cloning). They go as far as stealing Credit Card ID. Basically, once they are able to steal the confidential data of a user, they can buy things online. Furthermore, they can even apply for a loan with your details. Truthfully, they can do pretty much anything they imagine with your credentials.
3. ID Document Forgery:
More recently, cyber criminals and fraudsters can buy ID proof of a person. When they do, they can use it to login to a system, make use of it. The worse part is that they do this without any impact on themselves. Conventionally, this type of fraudulent activity can put several companies at risk. This is because, fraudsters can get access to their computer systems & faking an ID Document to cheat them. To be sincere, these fraudsters are very skilful in creating many original IDs. Therefore, obsolete systems which are used for preventing Identity forging are no longer effective. Why? Because they are no longer capable of detecting these forgeries. Therefore, these patterns require continuous updating. With that in our minds, Machine Learning algorithms are the best tool for forgery protection. ML evolves with more dataset as well as showing consistent higher detection rates as time flies.
4. Identity Theft:
Just as the name implies, attackers can steal your identity. Cybercriminals can therefore hack their way into a victims accounts. They gain access into the owner’s credentials such as; name, bank account details, email address, passwords, etc. Consequently, they can make use of these credentials to cause harm to their victim. Currently, there are about 3 types of identity theft: (i) synthetic theft (ii) real name theft (iii) account takeover.
Recommended Solutions
- Protecting Credentials and Company Secrets with DLP
- Under Cyber Attack? – How Companies Are Protecting their Data
Manual Review and Transaction Rules
These days, Machine Learning in Artificial Intelligence resolves most of the issues that people cannot deal with. Before now, industries were previously using a rule-based approach for fraud detection. However, because of the popularity as well as acceptance of A.I, especially by students, Machine Learning have migrated from the ruled-based fraud detection to ML-based solutions. This is happening in every industry vertical, organisations etc.
So, we can review the rule-based fraud detection system and ML-based systems.
Previous Post:
- How To Learn Artificial Intelligence for Free [7 Steps]
- How Businesses can Benefit from Artificial Intelligence
- DNS Cache Poisoning Detection & Attacks Prevention
Rule-based Approach or Traditional Approach in Fraud Detection Algorithms
First and foremost, in the rule-based approach, the algorithms are written by fraud analysts. They are basically on very strict rules. If any changes have to be made for detecting a new fraud, then they are done in two ways. Either by creating new algorithms or by manually making those changes in the already existing algorithms. Now, in this approach, because of the increasing number of customers/data, human effort also increases. That is to say, the rule-based approach is time-consuming, costly, require skills etc.
There is another disadvantage of the rule-base approach. It is more likely to have false positives results. Basically, this is an error condition where an output of a test specifies the existence of a particular condition that does not even exist at all. Ideally, the output of a transaction solely depends upon the rules and guidelines made for training the algorithm for non-fraudulent transactions/payments. Therefore, for a fixed risk threshold, if a transaction is rejected where it should not be, it will generate a condition of high rates of false positives. On the long run, this false-positive condition will result in losing genuine customers/clients.
ML-based Fraud Detection Algorithms
Looking at the rule-based approach, we saw that the algorithms cannot recognize the hidden patterns. Why? Since we know that they are based on strict rules, they cannot predict fraud by going beyond these rules. However, in real life, cyber criminals are very skilled. They can always adopt new techniques every time to commit a crime. On this account, there is a requirement for a security system that can analyze patterns in data. They should be able to predict and respond to new situations for which it is not explicitly programmed or trained for.
Because of this, we make use of Machine Learning for detecting fraudulent activities. With this, a given machine tries to learn by itself and becomes better by experience. In addition, it is an efficient way of detecting fraudulent acts due to its speedy & fast computing process. Another advantage is that it does not even require the guidance of a fraud analyst. Also, it helps in reducing false positives for transactions. How? Since the patterns are detected by an automated system for streaming transactions that are in huge volume.
Going forward, lets take a quick look at the two most commonly used Machine Learning models for detecting fraud in transactions.
Supervised Learning Used in Fraud Detection Algorithms
The Supervised Learning models are trained on tagged outputs/results. So, if a transaction occurs, it is tagged as either ‘fraud’ or ‘non-fraud.’ Its simple as that. Large amounts of such tagged data are fed into the supervised learning model. What’s the reason? It is done in order to train it in such a way that it gives a valid output. Additionally, the accuracy of the model’s output depends on how your data is organised.
You can Kick-start your career in Artificial Intelligence with the perfect Artificial Intelligence Course now!
Unsupervised Learning Used in Fraud Detection Algorithm
For the unsupervised learning, models are built to detect unusual behavior in transactions which has not been detected before. Furthermore, these unsupervised learning models involve self-learning that assists in locating hidden patterns in transactions. In this type, the model tries to do three things. First, learn by itself. Secondly, analyzes the available data. Lastly, it tries to find the similarities and dissimilarities between the occurrences of transactions. You will agree that this helps in detecting fraudulent activities online.
With the explanation above, both these models; supervised and unsupervised, can be used independently. they can also be used in combination for detecting anomalies in transactions.
What is the Need for the Fraud Detection Machine Learning Algorithms?
People around the world always search for methods, tools, or techniques that reduce their workload. They try to reduce human effort for performing a certain task efficiently. So, in Machine Learning, algorithms are designed in such a way that they try to learn by themselves using past experience. Now, after learning from the past experience put it to use. The algorithms will become quite capable of reacting and responding to conditions for which they are not explicitly trained. So you can see that Machine Learning helps a lot when it comes to fraud detection. Furthermore, it tries to identify hidden patterns that help in detecting fraud which has not been previously recognized. its benefit is that, its computation is fast as compared to the traditional rule-based approaches.
Why do we use Machine Learning in Fraud Detection?
Written below are some factors why Machine Learning techniques are so popular and widely used in industries for detecting frauds:
Speed:
Computers/Robots are faster than human beings. So Machine Learning is widely used because of its very fast computations. It can quickly analyse/process data as well as extract new patterns from it within no time. Humans are slower in this regards. look at it this way; for human beings to evaluate the data, it will take a lot of time. Evaluation time will even increase with the amount of data. The Rule-based fraud prevention systems are based on written rules for permitting which type of actions are deemed safe and which one’s must raise a red-flag of suspicion.
In the 21st century, this Rule-based system is inefficient because it takes so much time to write these rules for different scenarios. This is exactly where Machine Learning based Fraud Detection algorithms comes in. They succeed in not only learning from these patterns it is capable of detecting new patterns automatically. Besides, it does all of this seemingly in a fraction of the time that these rule-based systems could achieve. This is the reason why Robots are taking more jobs from Humans.
Scalability:
Definition: Scalability is the measure of a system’s ability to increase or decrease in performance and cost in response to changes in application and system processing demands. Therefore, as more and more data is fed into the Machine Learning-based model, the model becomes more accurate and effective in its prediction. Rule-based systems don’t evolve by themselves. This is because professionals who developed these systems must write these rules meeting various circumstances. But for Machine Learning based algorithms, a dedicated team of Data Science professionals must be involved in making sure these algorithms are performing as intended. See the role of a Data Scientist in an organisation.
Efficiency:
The ratio of the useful work performed by a machine or in a process to the total energy expended or heat taken in is know as efficiency. Therefore, Machine Learning algorithms perform the redundant task of data analysis and try to find hidden patterns repetitively. So, their efficiency is better in giving results in comparison with manual efforts. It avoids the occurrence of false positives which counts for its efficiency. Because of their efficiency in detecting these patterns, the specialists in Fraud detection could now focus on more advanced and complex patterns. They can now leave the low or moderate level problems to these Machine Learning based algorithms.
How does a Machine Learning system work for Fraud Detection? Diagram Explanation
The below picture shows the basic structure of the working of fraud detection algorithms using Machine Learning:
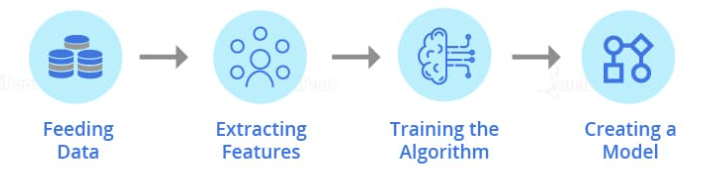
1. Feeding Data:
First of all, the data is fed into the model. The accuracy of the model depends on the amount of data on which it is trained. Therefore, the more data better, the model performs well.
It is for detecting frauds specific to a particular business. But you need to input plenty amounts of data into your model. As such, this will train your model in such a way that it detects fraud activities specific to your business perfectly well.
2. Extracting Features:
The Feature extraction basically works on extracting the information of each and every thread associated with a transaction process. These can be the location from where the transaction is made. It can be the identity of the customer, the mode of payments, or even the network used for online transaction.
- Identity: This parameter is used to check a customer’s email address, mobile number, etc. and it can check the credit score of the bank account if the customer applies for a loan.
- Location: It checks the IP address of the customer and the fraud rates at the customer’s IP address and shipping address.
- Mode of Payment: It checks the cards used for the transaction, the name of the cardholder, cards from different countries, and the rates of fraud of the bank account used.
- Network: It checks for the number of mobile numbers and emails used within a network for the transaction.
3. Training the Algorithm:
Once you have created a fraud detection algorithm, you need to train it by providing customers data so that the fraud detection algorithm learns how to distinguish between ‘fraud’ and ‘genuine’ transactions.
4. Creating a Model:
In this model, if you have trained your fraud detection algorithm on a specific dataset, you are ready with a model that works for detecting ‘fraudulent’ and ‘non-fraudulent’ transactions in your business.
Benefit: The advantage of Machine Learning in fraud detection algorithms is that it keeps on improving as it is exposed to more data.
There are many techniques in Machine Learning used for fraud detection. Here, with the help of some use cases, we will understand how Machine Learning is used in fraud detection.
Learn more about Machine Learning from this Machine Learning Training in New York to get ahead in your career!
Techniques of Machine Learning for Fraud Detection Algorithms
Fraud Detection Machine Learning Algorithms Using Logistic Regression:
Logistic Regression is a supervised learning technique that is used when the decision is categorical. It means that the result will be either ‘fraud’ or ‘non-fraud’ if a transaction occurs.
Use Case: Let us consider a scenario where a transaction occurs and we need to check whether it is a ‘fraudulent’ or ‘non-fraudulent’ transaction. There will be given set of parameters that are checked and, on the basis of the probability calculated, we will get the output as ‘fraud’ or ‘non-fraud.’
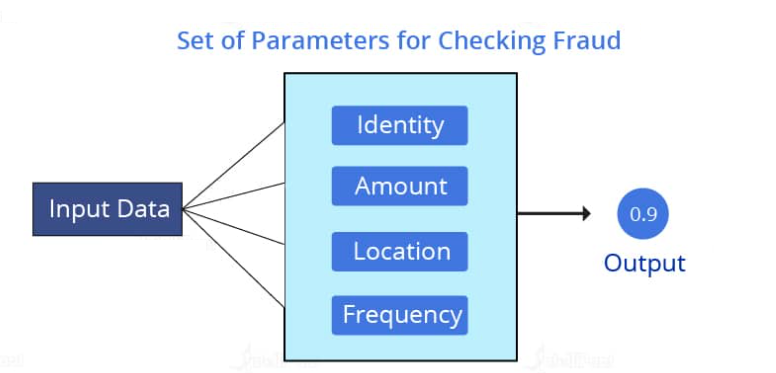
In the diagram above, it can be seen that the probability calculated is 0.9. This directly means that there is a 90% chance that the transaction is ‘genuine’ and there is a 10% probability that it is a ‘fraud’ transaction.
Fraud Detection Machine Learning Algorithms Using Decision Tree:
Decision Tree algorithms in fraud detection are used where there is a need for the classification of unusual activities in a transaction from an authorized user. These algorithms consist of constraints that are trained on the dataset for classifying fraud transactions.
Use Case: Let us consider a scenario where a user makes transactions. We will build a decision tree to predict the probability of fraud based on the transaction made.
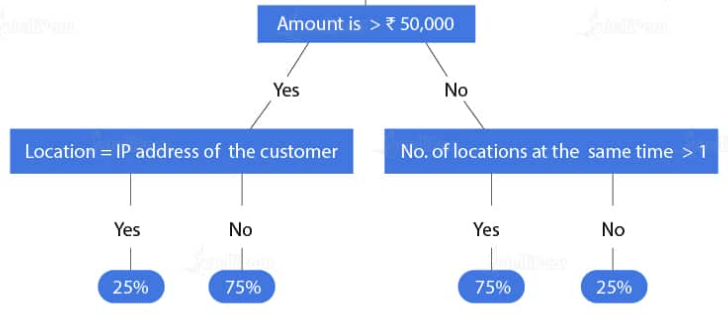
- First, in the decision tree, we will check whether the transaction is greater than $10,000. If it is ‘yes,’ then we will check the location where the transaction is made.
- And if it is ‘no,’ then we will check the frequency of the transaction.
- After that, as per the probabilities calculated for these conditions, we will predict the transaction as ‘fraud’ or ‘non-fraud.’
- Secondly, if the amount is greater than $10,000 and location is equal to the IP address of the customer, then there is only a 25 percent chance of ‘fraud’ and a 75 percent chance of ‘non-fraud.’
- Similarly, if the amount is greater than $10,000 and the number of locations is greater than 1, then there is a 75 percent chance of ‘fraud’ and a 25 percent chance of ‘non-fraud.’
- Lastly, this is how a decision tree in Machine Learning helps in creating fraud detection algorithms.
Now, we will look at the random forest in Machine Learning used in fraud detection algorithms.
Want to know more about Machine Learning? Check out the AWS Machine Learning Training in Sydney!
Fraud Detection Machine Learning Algorithms Using Random Forest:
Random Forest uses a combination of decision trees to improve the results. Each decision tree checks for different conditions. They are trained on random datasets and, based on the training of the decision trees, each tree gives the probability of the transaction being ‘fraud’ and ‘non-fraud.’ Then, the model predicts the result accordingly.
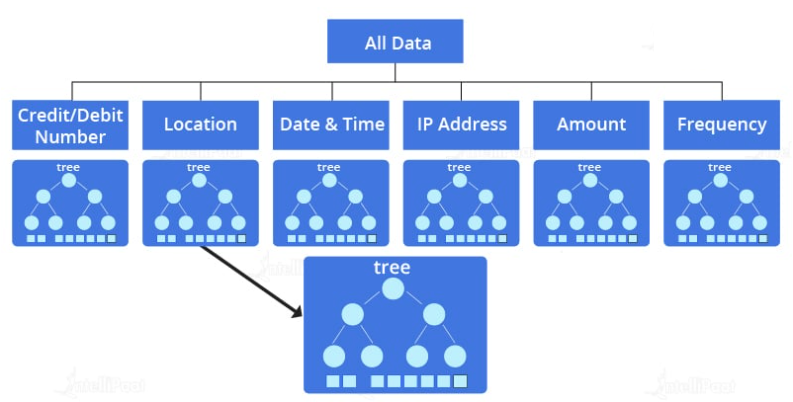
Use Case: Let’s consider a scenario where a transaction is made. Now, we will see how the random forest in Machine Learning is used in fraud detection algorithms.
Here, when a request for a transaction is given to the model, it checks for some key information. Such as the credit/debit card number, location, date, time, the IP address, the amount, as well as the frequency of the transaction. So, all this details is fed as an input into the fraud detection algorithm. After that, this fraud detection algorithm selects variables from the given dataset that help in splitting up of the dataset. The above diagram shows the splitting up of the dataset into multiple decision trees.
So, the sub-trees consist of variables and the conditions to check those variables for an authorized transaction.
After checking all the conditions, all the sub-trees will give the probabilities for a transaction to be ‘fraud’ and ‘non-fraud.’ Based on the combined result, the model will mark the transaction as ‘fraud’ or ‘genuine.’
This is how a random forest in Machine Learning is used in fraud detection algorithms.
Fraud Detection Machine Learning Algorithms Using Neural Networks:
Neural Networks is a concept inspired by the working of a human brain. Neural networks in Deep Learning uses different layers for computation. First of all, it uses cognitive computing that helps in building machines capable of using self-learning algorithms that involve the use of data mining, pattern recognition, and natural language processing. Secondly, it is trained on a dataset passing it through different layers several times.
Lastly, it gives more accurate results than other models as it uses cognitive computing and it learns from the patterns of authorized behavior and thus distinguishes between ‘fraud’ and ‘genuine’ transactions.
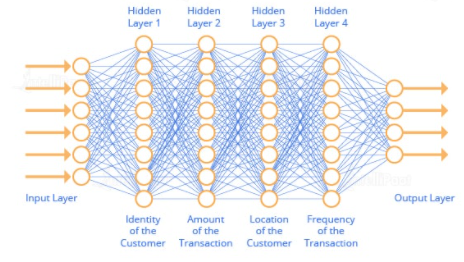
Use Case: Now, let us take a look at an example where a neural network is used for fraud detection. There are several layers in a neural network that focus on different parameters to make a decision whether a transaction is ‘fraud’ or ‘non-fraud.’ In the below diagram it is shown how the layers of neural networks represent and work on different parameters.
Conclusion
In conclusion, the data is fed into the neural network. After that, the Hidden Layer 1 checks the amount of transaction, and similarly other layers check for the location, identity, IP address of the location, the frequency of transaction, and the mode of payment. There can be more business-specific parameters. However. these individual layers work on these parameters, and computation is done based on the models’ self-learning and past experience to calculate the probabilities for detecting frauds.
Thus, neural networks work on data and learn from it, and it improves the model’s performance over every iteration.
This is how neural networks are used for implementing fraud detection algorithms.
Finally, in this blog, we have seen how fraud detection algorithms work using Machine Learning techniques. Such as logistic regression, decision tree, random forest, and neural networks. This technology is improving day by day so that it provides us more accuracy and better results to prevent fraud.
Future Learn Data Science on Microsoft Azure Using Python Programming Course
Top Paying Cloud Computing and Security Courses Online Classes with Certificate
FedEx Text Scam Alert 2021 Updates: Fake Delivery Notifications SMS & Email
What You Need to Know About Scam SMS & Email this Year





